For the past five years No Magic has been engaged in the research and development of our next generation repository for collaborative development and versioned storage of models. We have adopted a long term perspective in this work, because we anticipate that the next decade will see a significant increase in the scale of models that our tools must enable users to work with. A key driver behind this trend is the adoption of MBSE making modeling increasingly ubiquitous in development organizations. Moreover, we have noticed that some of our customers are already approaching the limits in scale that current tools support, and with the adoption of MBSE to model larger and larger systems the need for modeling at large scale will keep growing.
We have considered the following dimensions of scalability:
- model size / number of elements
- number of concurrent users
- memory
- processing
To ensure the ability to scale in each of these dimensions, we must not only distribute the work across several servers, but also achieve horizontal scalability. Horizontal scalability of a distributed system means that the capacity of that system increases linearly with the number of servers. So a cluster of 8 nodes will handle twice the number of users and twice the amount of data that a cluster with four nodes does. And 16 nodes will again handle twice the load of an 8 node cluster. Moreover, as far as processing is concerned, a larger cluster will have better performance on the same workload as long as it is parallelizable.
We achieve this level of scalability in our tools in part by building a model repository that leverages the techniques developed for big data over the past decade. This allows the repository itself to handle extremely large models. This, however, only addresses part of the challenge of large scale modeling. To be able to work with large models in practice we must also provide a way for MagicDraw users to create, edit and collaborate on large models. When a single model can be too large to be downloaded in entirety to a client, it follows that we must enable MagicDraw and other clients to work with partial models. This is illustrated below:
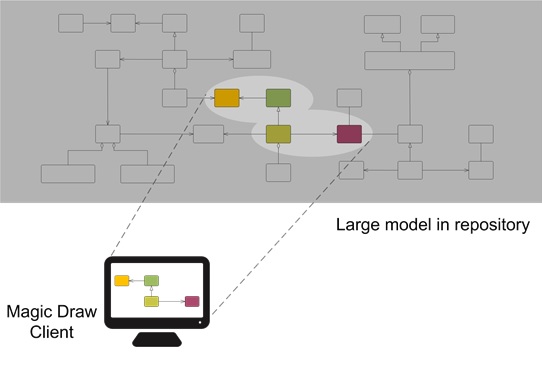 While a model may be large, a user only ever needs direct access to the part of a model that he or she is working on at any given moment. This dynamic view of a model is realized by continuously updating the set of model elements available locally on a client. The inherent challenge in this approach, is that accessing data from a repository over a network connection is inherently slower than accessing local storage. To address this challenge and achieve good performance in practice, the repository client integrated in Magic Draw employs sophisticated algorithms to perform predictive and on-demand retrieval of model data from the repository.
While a model may be large, a user only ever needs direct access to the part of a model that he or she is working on at any given moment. This dynamic view of a model is realized by continuously updating the set of model elements available locally on a client. The inherent challenge in this approach, is that accessing data from a repository over a network connection is inherently slower than accessing local storage. To address this challenge and achieve good performance in practice, the repository client integrated in Magic Draw employs sophisticated algorithms to perform predictive and on-demand retrieval of model data from the repository.
Plug-in API
Models are by nature graphs and so there are certain cases, like validation, that can require global processing of a model. Moreover, custom use cases of model data may also need to process an entire model. To ensure that the processing capabilities required in such use cases scale in accordance with the models themselves, we are implementing an API for server side plug-ins that enable implementation of custom processing and access to models. This way the functionality of the model repository can be extended to realize custom APIs for domain specific clients and use cases. To ensure that we provide a soundly designed API, we use it ourselves to realize part of the features of the repository itself.
Enhanced Enterprise Features
While the challenge of large scale modeling is a key driver for the architecture of our new model repository, it will also include and extend the features matured in our current Teamwork Server solution. Among the major new features we will provide in the first release is Role Based Access Control to enable efficient management of users’ access rights across the enterprise.
Looking a bit further ahead, we are working on a new collaboration model based on our experience with and feedback on the Teamwork Server solution. This collaboration model will facilitate efficient collaboration among more users, on larger models, while retaining the strong support for model integrity preservation that Teamwork Server features.
This is the second post in the series. See the first post “Scalable Collaborative Solution Leads to Big Opportunities“